



Quick Study of Bring Your Own Vulnerable Driver (BYOVD)
Quick Study of BYOVD including Root Cause Analysis and how it can be abused by attackers to disable or evade security solutions.
Recently, I was tasked to try out challenge 2 DudeLocker in Flare-on from the year 2016. Since there are already many writeups, this post aims to help the reader understand a concept that was really hazy to me. The concept that I have questions about is how PE files deal with import functions and how they resolve them.
What DudeLocker does is that it will attempt to generate the IV and Key and use that for AES-CBC Mode Cipher to encrypt every document in the Briefcase folder stored in the Desktop. However, what we really want is decrypt the file instead to get back the original jpg file content. One of the ways to do so is to mess with the Import descriptors and calling CryptDecrypt rather than CryptEncrypt. This will still work because AES-CBC uses symmetric encryption.
If you have not tried this yet, you can download the challenge files from github. Give it a try and you can try to follow along as well!
During this time, I wil be using pe-bear and pestudio to inspect the PE File structure of the ransomware. Within the NT Headers, there is an Optional Header that points to the Import Directory at raw file offset 0x160 which contains the address 0x21A8.
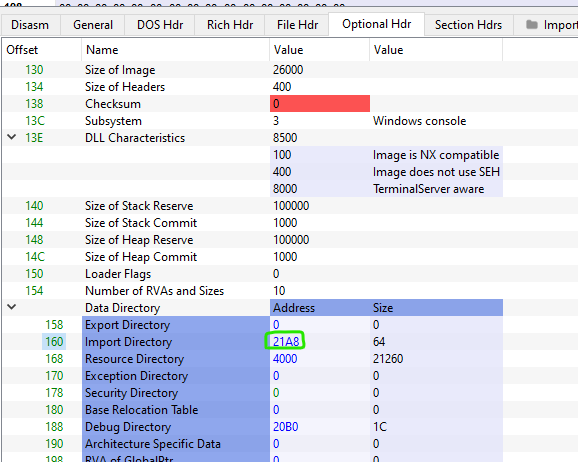 Address of Import Directory
Address of Import Directory
While this address looks pretty much normal, however, when we look at the data in the last section, realize that there is no such address as it ends at 0x19FF. WHAT?!
To understand this, we have to understand what Relative Virtual Address is! According to Wikipedia :
Relative virtual addresses (RVAs) are not to be confused with standard virtual addresses. A relative virtual address is the virtual address of an object from the file once it is loaded into memory, minus the base address of the file image.
That said, to find out the directory information from the PE File, we need to calculate the File Offset Address (FOA) so that we can parse the data.
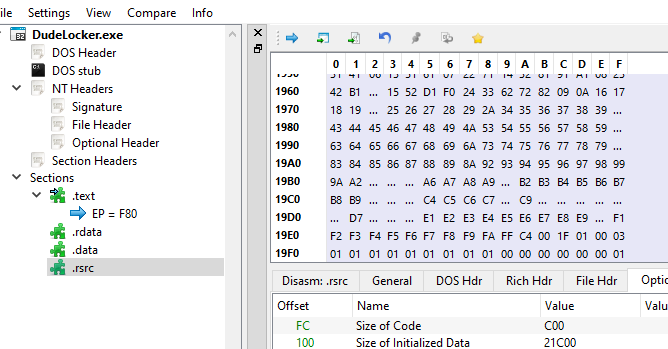
Before going deeper, let us first take a look and understand the Section Headers that can be seen in PE-bear.
 Section Headers
Section Headers
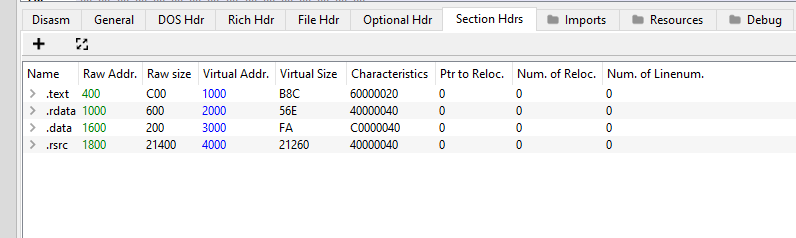
We are interested in the .rdata section since the the RVA of value 0x21A8 is within range. We see that there are quite a number of fields in this Section Headers.
This actually corresponds with the _IMAGE_SECTION_HEADER struct.
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
The two main fields that we are interested in are :
Now, the value 0x21A8 represents the Relative Virtual Address (RVA) of the Import Directory which refers to the address when loaded in memory at that specific location relative to the image base.
Therefore, to figure out the File Offset Address with relations to the Relative Virtual Address (RVA), we can do the following calculation.
FileOffsetAddress = PointerToRawData + (RVA - VirtualAddressOfSection)
FileOffsetAddress = 0x1000 + ( 0x21A8 - 0x2000 )
FileOffsetAddress = 0x11a8
(RVA - VirtualAddressOfSection) acts like the delta between the address and the first byte which will then be added to Pointer to Raw Data where the first byte of that section is located in the PE File. Thus, getting the File offset Address.
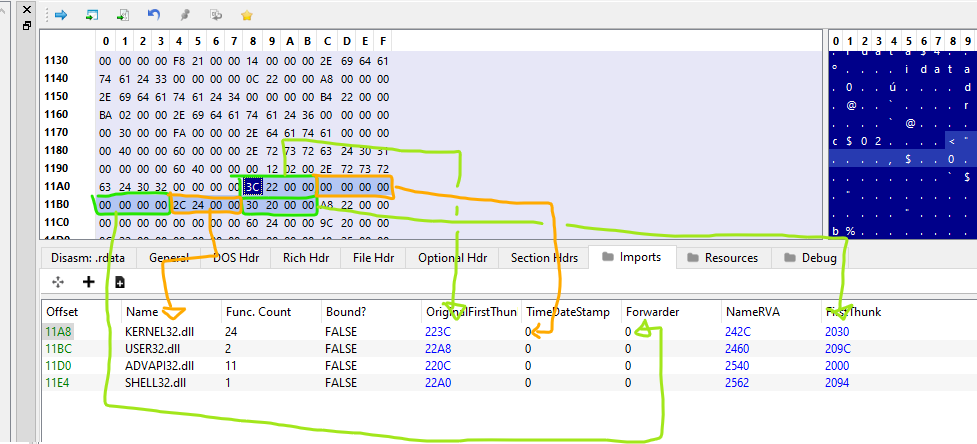
Checking the first entry in the imports tab in PE-bear should confirm our calculations!
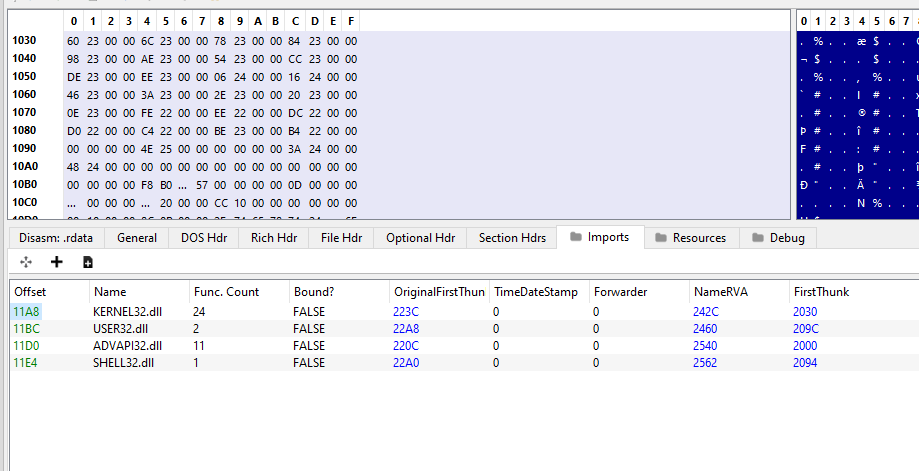 At file offset 0x11a8 lies the first import entry
At file offset 0x11a8 lies the first import entry
Referencing this PDF, the Import Descriptors contain the fields as seen in the previous image. This old MSDN Post supports that as well. It turns out there are different ways to resolve the imported function address. For this post, I will only focus on resolution when bound value is set to FALSE.
The following image is taken from the aforementioned PDF
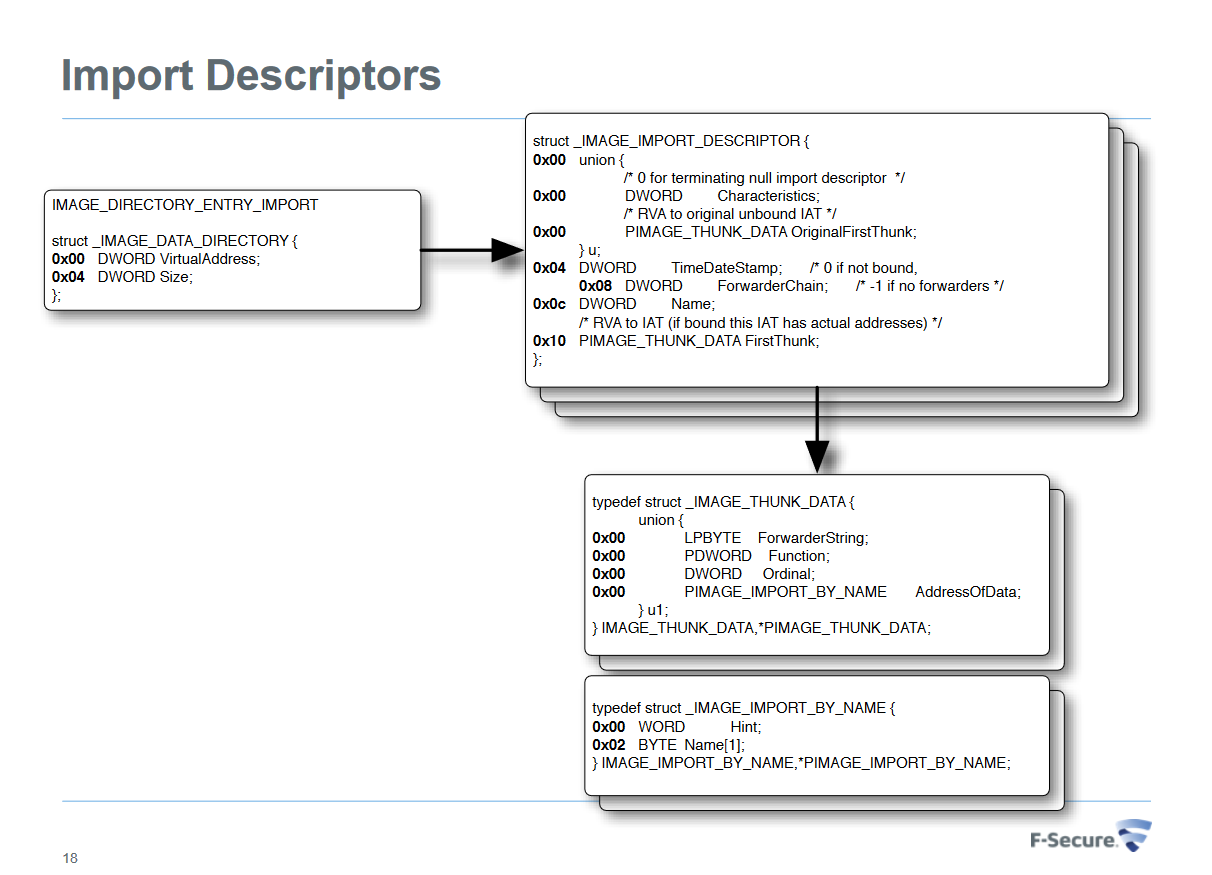
Using this data structure, we should be able to parse and get back the same result.
 Mapping from memory to structure
Mapping from memory to structure
Now that we see this mapping, there is still something that did not make sense. To get the name, we can look at the Image thunk data which is a RVA to the original unbounded IAT.
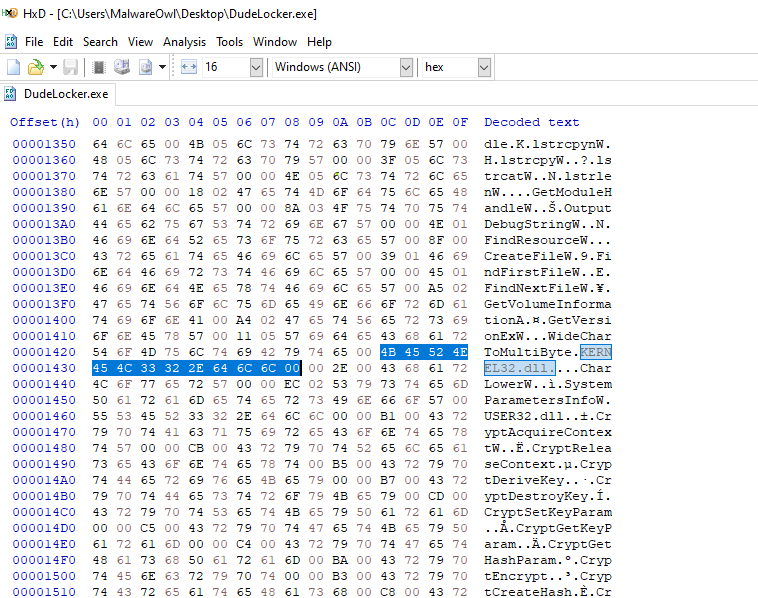
Notice how the value of NameRVA 0x242c gets resolved to the symbol name KERNEL32.dll? We can confirm that with the same calculations as before to find out the File Offset Address.
FileOffsetAddress = PointerToRawData + (RVA - VirtualAddressOfSection)
FileOffsetAddress = 0x1000 + ( 0x242c - 0x2000 )
FileOffsetAddress = 0x142c
Finally, to list out the import functions, we can trace through the Original first Thunk. Since we have the value fo 0x223c, we have the FileOffsetAddress of 0x123c which contains the RVA of 0x2360 which points to IMAGE_IMPORT_BY_NAME structure with the hint and byte pointer field at 0x1360!
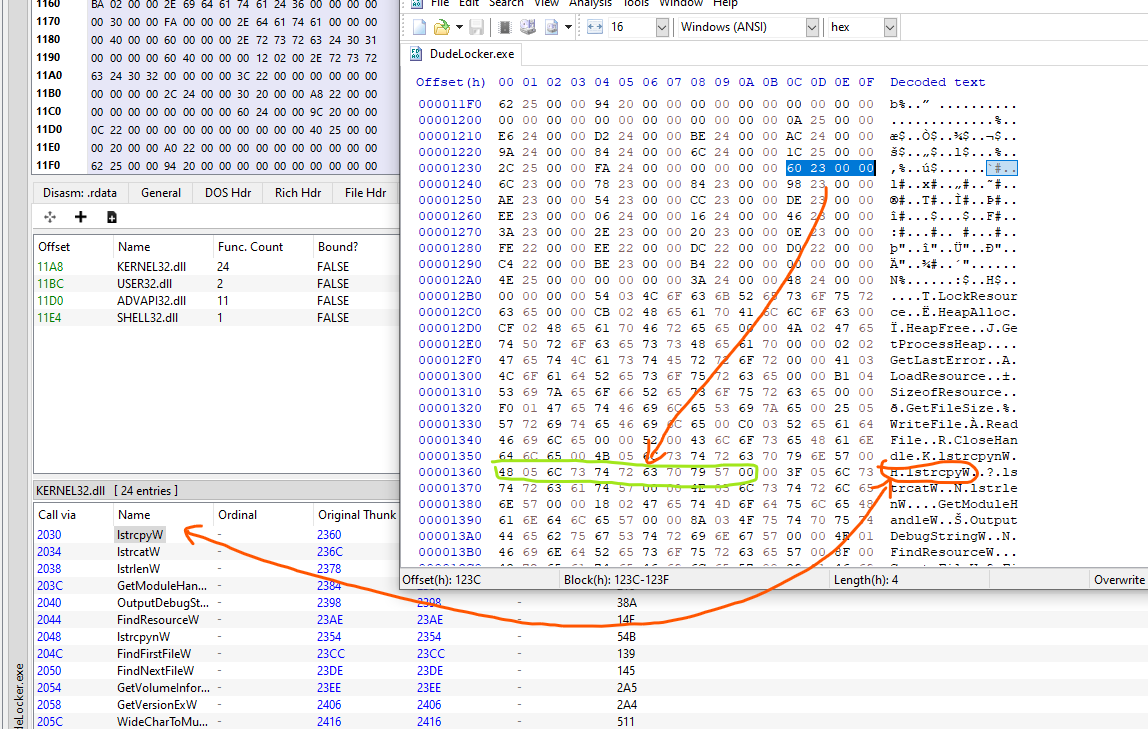
The hint in this data structure is actually a “hint” to the loader as to what ordinal of the imported API might be. Also, the reason why we can tell that the RVA of 0x2360 points to the IMAGE_THUNK_ DATA value is because the high bit of the IMAGE_THUNK_DATA value is not set. If it is set, the bottom 31 bits (or 63 bits for a 64-bit executable) is treated as an ordinal value.
Another important detail is that this “hint” is there to help improve performance when attempting to resolve a function, however, if it is unable to find the function, it will still search the normal way as before. This means that if we were to change the name of the function, the hint may fail and still continue to search up the DLL export table.
If you have done the challenge, you would have been familiar with the following two functions.
// 7 parameters
BOOL CryptEncrypt(
[in] HCRYPTKEY hKey,
[in] HCRYPTHASH hHash,
[in] BOOL Final,
[in] DWORD dwFlags,
[in, out] BYTE *pbData,
[in, out] DWORD *pdwDataLen,
[in] DWORD dwBufLen
);
// 6 parameters
BOOL CryptDecrypt(
[in] HCRYPTKEY hKey,
[in] HCRYPTHASH hHash,
[in] BOOL Final,
[in] DWORD dwFlags,
[in, out] BYTE *pbData,
[in, out] DWORD *pdwDataLen
);
For this, since we are now familiar with how the program resolves the name, we can attempt to find and patch the binary so that.
First thing I did was to change the name using CFF Explorer. I changed the name of CryptEncrypt to CryptDecrypt.
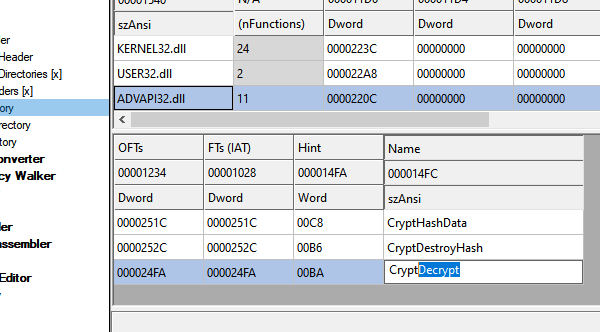
We can now load the binary into IDA and see the changes.
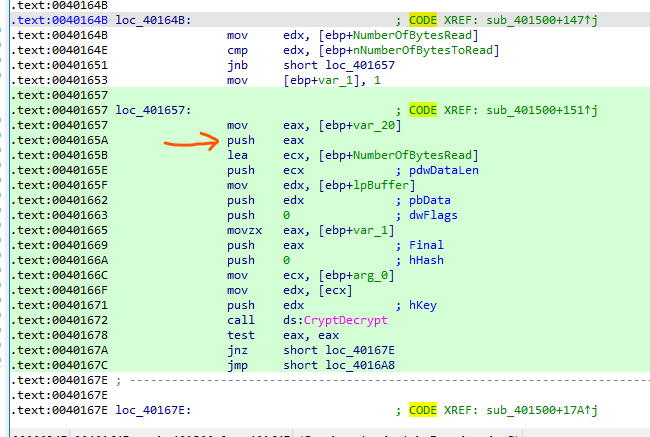
Since that CryptDecrypt has the exact same parameters except for the absence of the parameter dwBufLen, we can replace the push eax instruction with NOPs at address 0040165A.
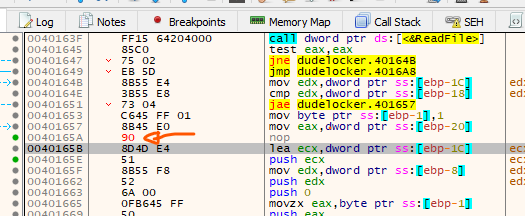
Let’s patch it in x32dbg and see the result. Remember to change the volume serial number with VolumeId64.exe from sysinternal tools suite. Also, put the BusinessPapers.doc file into the Briefcase as well for decryption.
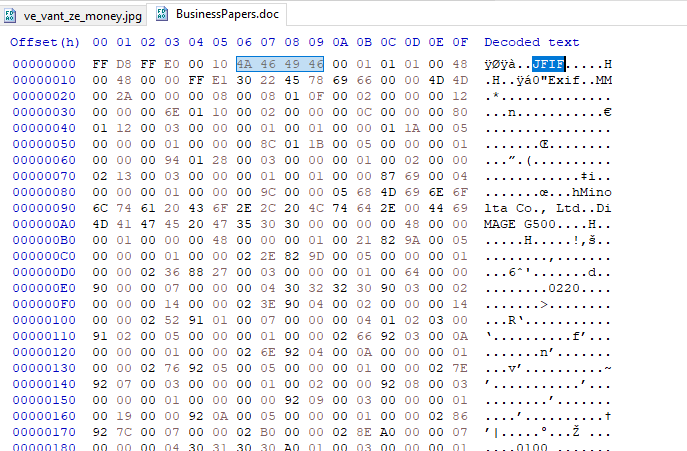
After running the decryption, we can now double check the BusinessPapers.doc in HxD. We see that it has the JFIF header with Exif information which suggest strongly that this is a JPG file.
Changing the extension to Jpg and we should see the following image containing the flag.

Quick Study of BYOVD including Root Cause Analysis and how it can be abused by attackers to disable or evade security solutions.
A quick writeup on a Virtual Machine Based CTF Challenge.
This year of flare-on is the third try and the first that I have ever completed so far! Definitely did have my share of pain and joy during this time of challenges. For this post, I will share my writeup on challenge 9 and 11.




%20-%20RVA%20and%20Import%20Descriptors){kind=link}